2. Preparing your Data¶
2.1. Transcription Files¶
The input to the force aligner is a wav file and the orthographic transcription associated with it. Transcriptions can be in either .TextGrid or .txt formats.
2.1.1. .TextGrid transcription¶
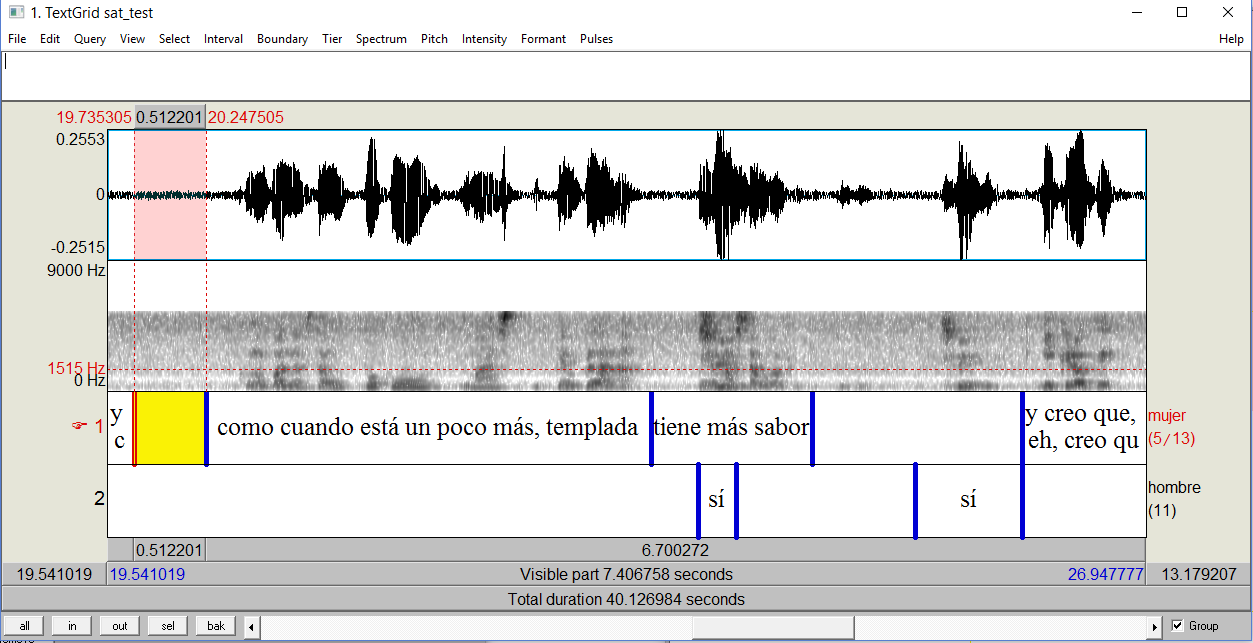
Example TextGrid Transcription
It is strongly suggested to use transcriptions in Praat TextGrid format as in the above example. This approach has many benefits over the .txt transcription approach:
- Each speaker on a separate tier: more accurate alignments, especially in overlap or noisy conditions
- Exclusion of non-transcribed sections: the aligner will only align where there is transcribed speech, this is helpful for ignoring speech not of interest to the analysis.
- Aligning in small intervals: each interval is aligned separately, increasing accuracy.
- Definition of speaker labels through tier names
2.1.2. .txt transcriptions¶
{S1} pues yo como aquí, comida y o o bebes té y es más ma volcánico {LG} no puedo comer o o tomar el té durante quince minutos porque, está muy caliente
{S2} sí
{S1} y cuando la comida está muy caliente, en mi opinión, no tiene tanto sabor
{S2} sí
{S1} como cuando está un poco más, templada, tiene más sabor
{S2} sí
{S1} tiene más sabor
{S2} sí
{S1} y creo que, eh, creo que es porque en España, una cosa que he notado es que, normalmente las familias esperan hasta que todo el mundo esté sentado a la mesa,
{S2} sí
{S1} para comer
{S2} mhm
faseAlign also supports transcriptions in .txt format as in the above example. This approach has the benefit of not needing any determination of turn boundaries, but suffers from slightly poorer alignments. This is due to the fact that the entire wav file is aligned to the entire transcription. In this method, speakers cannot overlap in the output alignment (since the file is processed in one linear chunk).
Speakers are still separated into different tiers following alignment, through the use of speaker labels (e.g., {Julia}, {Speaker1}, {Marcos}) which mark utterances belonging to that speaker.
Note
Make sure to use the same speaker tags throughout the transcription. {Julia} and {JULIA} would be treated as two separate speakers.
2.2. Transcription Best Practices¶
Regardless of transcription method chosen, the process of transcribing is similar; you’ll want to pay attention to these key points:
- Be as Accurate as Possible! - This includes transcribing false starts, repetitions, omissions, etc as accurately as possible. The aligner can’t find a word if it’s not in the transcription!
- Transcribe in Breath Groups - While this is most helpful for the TextGrid transcriptions, I also find it helpful for the txt ones as well.
- Spell out all accents and tildes - otherwise words might be not be found in the dictionary
- Spell out all numbers and dates - (“El veinte de marzo” instead of “el 20 de Mar.”)
Additionally, the following can be used to note various non-speech items:
- {BR} - breath
- {CG} - cough
- {SIL} - silence longer than ~ 2 seconds
- {LG} - laughter
- {NS} - random noise
2.3. How to Add Missing Words¶
You’ll often run into words in your transcription that are not included in the dictionary; these may include place names, speech errors, novel words, etc. as decribed in Missing Words During Alignment.
If you want to override the automatic phonemicization (often appropriate for words not following native Spanish orthography to phonemes), add each of the missing words to a txt file with their corresponding phones, as shown below:
MATAMOROS m a t a m o r o s
TORREÓN t o R e o n
CAMPECHE k a m p e CH e
ZÚÑIGA s u NY i g a
GUASAVE g u a s a b e
ALLENDE a y e n d e
The format of the dictionary is the word (in captials) following by the corresponding phones, each separated by a space.
Phones correspond to ipa with the following exceptions:
- Palatal fricative: y
- Palatal affricatve: CH
- Palatal nasal: NY
- Alveolar tap: r
- Alveolar trill: R
- Approximants and stops are both lower-case: (b,d,g)
Note
Extra words in your custom dictionary won’t affect alignment! I suggest keeping one dict.local and adding new words as you encounter them.